# load liver package
library(liver)
# load cereal data which is included in the package
data(cereal)7 Data Wrangling
7.1 Welcome to the tidyverse!
Since R is open source, there are many different options for functions that can accomplish the same task. Over time, full sets of functions and packages have been developed with the purpose of working well together for data analysis and visualization.
In this class, we will use the tidyverse set of packages to visualize and wrangle data. This decision impacts the way that we will think about working with data (in a good way - in our opinion!).
In their own words, the tidyverse developers describe it as:
an opinionated collection of R packages designed for data science. All packages share an underlying design philosophy, grammar, and data structures.1
Most of the functionality you will need for an entire data analysis workflow will have the cohesive grammar of the tidyverse. Already, you have learned how to read in data with readr and visualize data with ggplot2.

7.2 Data Wrangling
We are going to keep working with the cereal dataset in the liver package. Take a minute to remind yourself what the data looks like!
head(cereal) name manuf type calories protein fat sodium fiber carbo
1 100% Bran N cold 70 4 1 130 10.0 5.0
2 100% Natural Bran Q cold 120 3 5 15 2.0 8.0
3 All-Bran K cold 70 4 1 260 9.0 7.0
4 All-Bran with Extra Fiber K cold 50 4 0 140 14.0 8.0
5 Almond Delight R cold 110 2 2 200 1.0 14.0
6 Apple Cinnamon Cheerios G cold 110 2 2 180 1.5 10.5
sugars potass vitamins shelf weight cups rating
1 6 280 25 3 1 0.33 68.40297
2 8 135 0 3 1 1.00 33.98368
3 5 320 25 3 1 0.33 59.42551
4 0 330 25 3 1 0.50 93.70491
5 8 -1 25 3 1 0.75 34.38484
6 10 70 25 1 1 0.75 29.50954str(cereal)'data.frame': 77 obs. of 16 variables:
$ name : Factor w/ 77 levels "100% Bran","100% Natural Bran",..: 1 2 3 4 5 6 7 8 9 10 ...
$ manuf : Factor w/ 7 levels "A","G","K","N",..: 4 6 3 3 7 2 3 2 7 5 ...
$ type : Factor w/ 2 levels "cold","hot": 1 1 1 1 1 1 1 1 1 1 ...
$ calories: int 70 120 70 50 110 110 110 130 90 90 ...
$ protein : int 4 3 4 4 2 2 2 3 2 3 ...
$ fat : int 1 5 1 0 2 2 0 2 1 0 ...
$ sodium : int 130 15 260 140 200 180 125 210 200 210 ...
$ fiber : num 10 2 9 14 1 1.5 1 2 4 5 ...
$ carbo : num 5 8 7 8 14 10.5 11 18 15 13 ...
$ sugars : int 6 8 5 0 8 10 14 8 6 5 ...
$ potass : int 280 135 320 330 -1 70 30 100 125 190 ...
$ vitamins: int 25 0 25 25 25 25 25 25 25 25 ...
$ shelf : int 3 3 3 3 3 1 2 3 1 3 ...
$ weight : num 1 1 1 1 1 1 1 1.33 1 1 ...
$ cups : num 0.33 1 0.33 0.5 0.75 0.75 1 0.75 0.67 0.67 ...
$ rating : num 68.4 34 59.4 93.7 34.4 ...Let’s start exploring the data. Maybe I want to look at the distribution of fiber for cereals from different manufacturers.
Recreate the plot below trying not to look at the code!

ggplot(cereal, aes(x = fiber)) +
geom_histogram() +
facet_wrap(vars(manuf)) +
labs(x = "Fiber (g)",
y = "",
subtitle = "Number of Cereals",
title = "Cereal Fiber by Manufacturer")Okay, there is a lot going on here and some manufacturers don’t have that many cereals anyway!
I would rather just look at the two biggest manufacturers, General Mills and Kelloggs and while I am at it, it would be nice to change the labels from “G” and “K” to these recognizable names. But how to do this?
Most of the the time, the data we have isn’t exactly what we need for a specific plot or analysis. This is where data wrangling, cleaning, and manipulation come in, which is the focus of the next couple of weeks of class.
Before jumping into any code, it is important to think about what the data is that we want for a plot or analysis and the steps that will take us from the current data to that version.
Check In
In groups, first draw the output that is described and then describe in words the steps you would take from cereal data to get the output for each of the following:
Plot just the fiber for Kelloggs and General Mills and make the manufacturer labels more clear.
What is the ratio of fiber to sugars in each cereal?
Create a new dataset that only has Nabisco cereals and displays the protein, fat, and sodium in each.
Create a table that shows, for each manufacturer the average and standard deviation of the grams of sugar in their cereals, along with how many cereals are in the data for each manufacturer. Order the table from most sugar (on average) to least.
7.3 dplyr for Data Wrangling
dplyr is part of the tidyverse that provides us with the Grammar of Data Manipulation.
- This package gives us the tools to wrangle, manipulate, and tidy our data with ease.
- Check out the
dplyrcheatsheet.
Each dplyr verb describes a common task for working with rectangular data. In all tidyverse functions, data comes first – literally, as it’s the first argument to any function.
In addition, you don’t use df$variable to access a variable - you refer to the variable by its name alone (“bare” names). This makes the syntax much cleaner and easier to read, which is another principle of the tidy philosophy.
The primary verbs are:
filter()/filter_out()arrange()select()mutate()summarize()- Use
group_by()to perform group wise operations - Use the pipe operator (
|>or%>%) to chain together data wrangling operations
Note that none of these dplyr verbs change the original object (which is typical for coding in R). You need to store your result if you want to use it as a new object.
7.3.1 filter() and filter_out()

Much of the time there are only certain observations in a dataset that you want to use in analysis and there may also be other observations that you want to remove for various reasons. filter() and filter_out() let us specify which rows to keep or get rid of in a dataframe.
filter() keeps only the rows that meet logical condition(s) we provide. The arguments for filter() are a data frame (or tibble) and logical conditions using bare variable names. Provided conditions that are separated with a comma , are combined using AND. Any row that would return TRUE based on the logical conditions is kept, while others are dropped.
Let’s only keep cereals with less than 5 grams of sugar by Quaker Oats.
filter(.data = cereal,
sugars < 5,
manuf == "Q") name manuf type calories protein fat sodium fiber carbo sugars
1 Puffed Rice Q cold 50 1 0 0 0.0 13 0
2 Puffed Wheat Q cold 50 2 0 0 1.0 10 0
3 Quaker Oatmeal Q hot 100 5 2 0 2.7 -1 -1
potass vitamins shelf weight cups rating
1 15 0 3 0.5 1.00 60.75611
2 50 0 3 0.5 1.00 63.00565
3 110 0 1 1.0 0.67 50.82839Note that there is no argument name for the logical conditions, they just directly follow the data.
Sometimes rather than thinking about keeping rows based on some criteria, it makes more sense to think about dropping rows based on a criteria. This is when the brand new filter_out() is useful!
Let’s remove cereals that are missing a rating OR has an illogical grams of sugar (-1).
clean_cereal <- filter_out(.data = cereal,
when_any(is.na(rating),
sugars < 0))
nrow(clean_cereal)[1] 76nrow(cereal)[1] 77We can see here, that cereal is unchanged, but one observation was dropped when creating clean_cereal.
Create a new dataset with only Kellogg’s and General Mills cereals.
More elegant solution using %in%:
filter(.data = cereal,
manuf %in% c("K", "G"))when_any() (or |) also gets you there:
filter(.data = cereal,
when_any(manuf == "K", manuf == "G"))Think about it – why is the first solution above preferable?
Check In
How can you join two logical statements with an “or” in
filter()?How can you join two logical statements with an “and” in
filter()?How can you join two logical statements with an “or” in
filter_out()?
7.3.2 piping operator |>
Okay now we at least have gotten down to the two manufacturers we are interested! Let’s use this data to create a new plot.
My first idea is that I could save a newdataset called plot_data and then make the plot with that dataset:
# save new data
plot_data <- filter(.data = cereal,
manuf %in% c("K", "G"))
# plot with that data
ggplot(plot_data, aes(x = fiber)) +
geom_histogram() +
facet_wrap(vars(manuf)) +
labs(x = "Fiber (g)",
y = "",
subtitle = "Number of Cereals",
title = "Cereal Fiber by Manufacturer")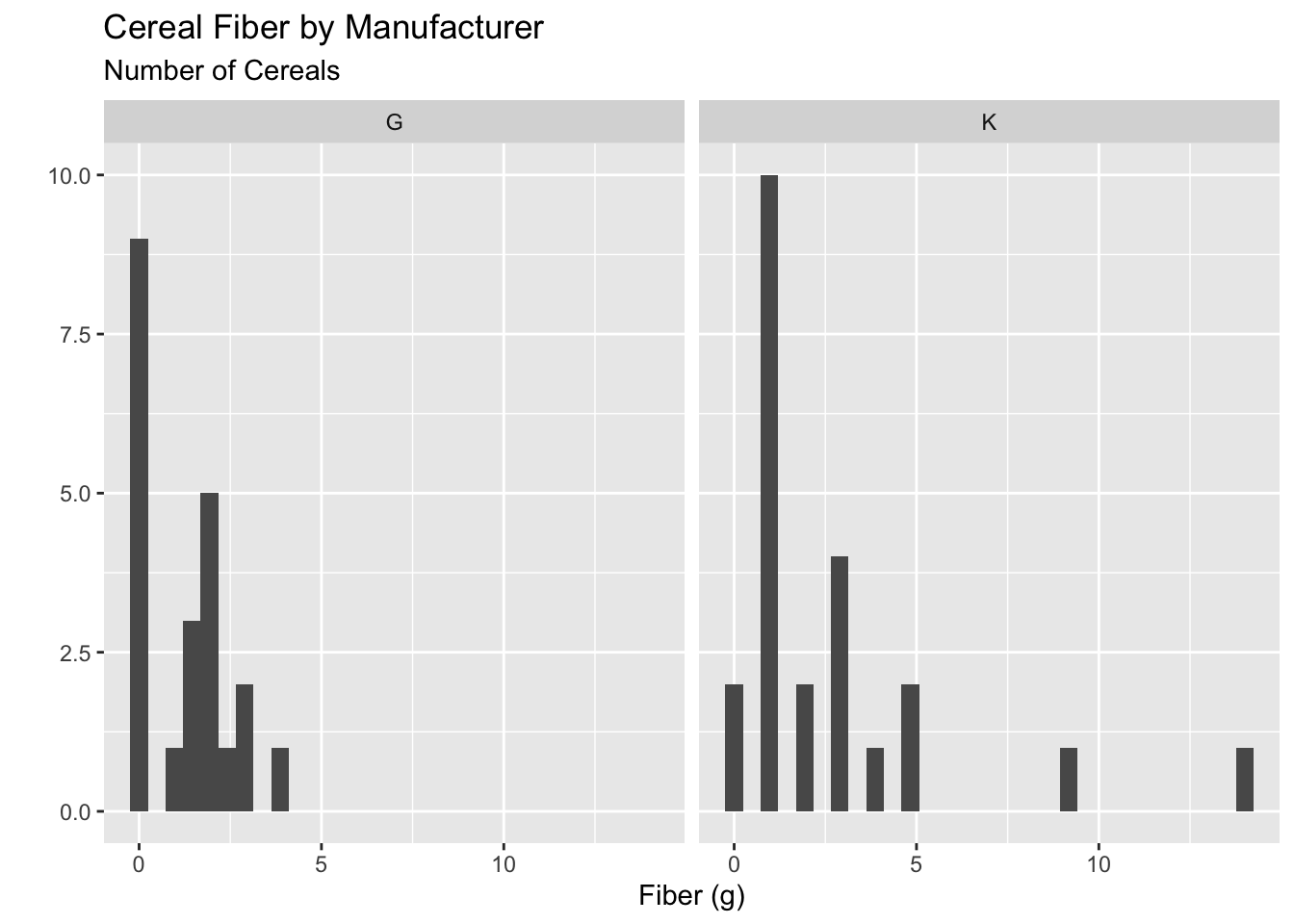
This is fine, but if I am not actually going to use my plot_data again, I don’t really need to save it.
Okay, instead I could put this new data into the data argument in ggplot:
ggplot(filter(.data = cereal,
manuf %in% c("K", "G")),
aes(x = fiber)) +
geom_histogram() +
facet_wrap(vars(manuf)) +
labs(x = "Fiber (g)",
y = "",
subtitle = "Number of Cereals",
title = "Cereal Fiber by Manufacturer")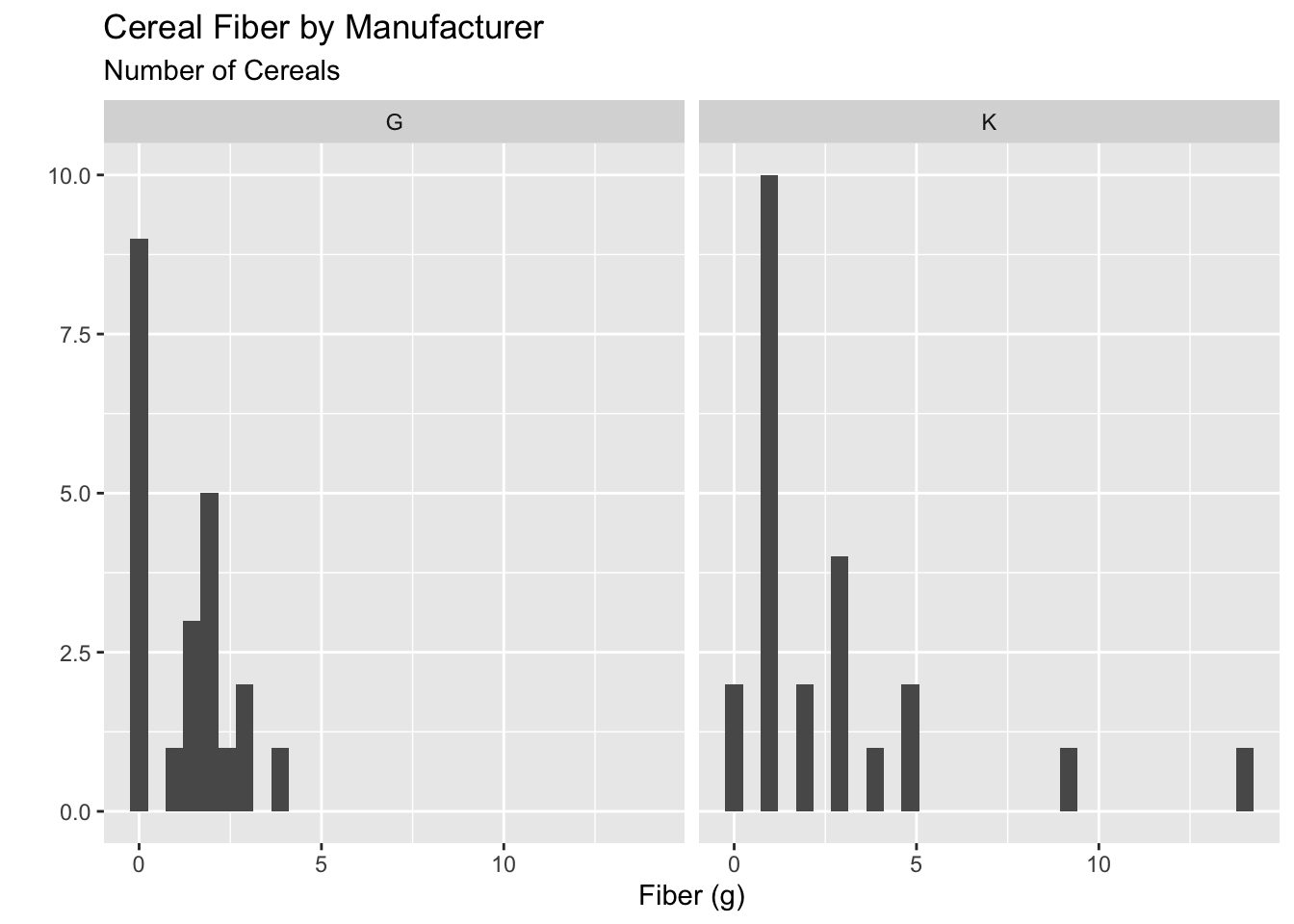
That definitely works, but it’s super hard to read and see what is going on!
This is where the piping operator comes in! The pipeing operator lets us “pipe” the output from one line of code into the next.
There are two piping operators: the native pipe |> and the original” pipe %>%. We will use the native pipe |>, but you will still see the “original” pipe around as an FYI.
The pipe operator takes whatever is to the left of it, and inputs that as the first argument in the function to the right.
For example, instead of head(x = cereal),
cereal |>
head() name manuf type calories protein fat sodium fiber carbo
1 100% Bran N cold 70 4 1 130 10.0 5.0
2 100% Natural Bran Q cold 120 3 5 15 2.0 8.0
3 All-Bran K cold 70 4 1 260 9.0 7.0
4 All-Bran with Extra Fiber K cold 50 4 0 140 14.0 8.0
5 Almond Delight R cold 110 2 2 200 1.0 14.0
6 Apple Cinnamon Cheerios G cold 110 2 2 180 1.5 10.5
sugars potass vitamins shelf weight cups rating
1 6 280 25 3 1 0.33 68.40297
2 8 135 0 3 1 1.00 33.98368
3 5 320 25 3 1 0.33 59.42551
4 0 330 25 3 1 0.50 93.70491
5 8 -1 25 3 1 0.75 34.38484
6 10 70 25 1 1 0.75 29.50954Building onto this, the first argument in filter() (and all other dplyr verbs) is the data .data =, so we can do:
cereal |>
filter(manuf %in% c("K", "G")) |>
head() name manuf type calories protein fat sodium fiber carbo
1 All-Bran K cold 70 4 1 260 9.0 7.0
2 All-Bran with Extra Fiber K cold 50 4 0 140 14.0 8.0
3 Apple Cinnamon Cheerios G cold 110 2 2 180 1.5 10.5
4 Apple Jacks K cold 110 2 0 125 1.0 11.0
5 Basic 4 G cold 130 3 2 210 2.0 18.0
6 Cheerios G cold 110 6 2 290 2.0 17.0
sugars potass vitamins shelf weight cups rating
1 5 320 25 3 1.00 0.33 59.42551
2 0 330 25 3 1.00 0.50 93.70491
3 10 70 25 1 1.00 0.75 29.50954
4 14 30 25 2 1.00 1.00 33.17409
5 8 100 25 3 1.33 0.75 37.03856
6 1 105 25 1 1.00 1.25 50.76500Again, this is so much better to read rather than
head(filter(.data = cereal, manuf %in% c("K", "G")))especially as our analyses get more complicated and with more steps!
We can put this all together for readable code for our plot! Note that the first argument in ggplot() is also the data.
cereal |>
filter(manuf %in% c("K", "G")) |>
ggplot(aes(x = fiber)) +
geom_histogram() +
facet_wrap(vars(manuf)) +
labs(x = "Fiber (g)",
y = "",
subtitle = "Number of Cereals",
title = "Cereal Fiber by Manufacturer")
7.3.3 arrange()
arrange() is a dplyr verb for sorting rows in the table by one or more variables. The arguments are data and one or more variables (separated by commas).
Arrange automatically sorts rows in ascending order based on the variable provided, so it is often used with a helper function, desc(), which reverses the order of a variable, sorting it in descending order.
Multiple arguments can be passed to arrange() to sort the data frame by multiple columns hierarchically; each column can be modified with desc() separately.
cereal |>
arrange(sodium) |>
head() name manuf type calories protein fat sodium fiber carbo sugars
1 Frosted Mini-Wheats K cold 100 3 0 0 3.0 14 7
2 Maypo A hot 100 4 1 0 0.0 16 3
3 Puffed Rice Q cold 50 1 0 0 0.0 13 0
4 Puffed Wheat Q cold 50 2 0 0 1.0 10 0
5 Quaker Oatmeal Q hot 100 5 2 0 2.7 -1 -1
6 Raisin Squares K cold 90 2 0 0 2.0 15 6
potass vitamins shelf weight cups rating
1 100 25 2 1.0 0.80 58.34514
2 95 25 2 1.0 1.00 54.85092
3 15 0 3 0.5 1.00 60.75611
4 50 0 3 0.5 1.00 63.00565
5 110 0 1 1.0 0.67 50.82839
6 110 25 3 1.0 0.50 55.33314cereal |>
arrange(desc(sodium)) |>
head() name manuf type calories protein fat sodium fiber carbo sugars
1 Product 19 K cold 100 3 0 320 1 20 3
2 Cheerios G cold 110 6 2 290 2 17 1
3 Corn Flakes K cold 100 2 0 290 1 21 2
4 Rice Krispies K cold 110 2 0 290 0 22 3
5 Corn Chex R cold 110 2 0 280 0 22 3
6 Golden Grahams G cold 110 1 1 280 0 15 9
potass vitamins shelf weight cups rating
1 45 100 3 1 1.00 41.50354
2 105 25 1 1 1.25 50.76500
3 35 25 1 1 1.00 45.86332
4 35 25 1 1 1.00 40.56016
5 25 25 1 1 1.00 41.44502
6 45 25 2 1 0.75 23.80404These functions implicitly arrange the data before slicing it (selecting rows).
slice_min()– select rows with the lowest value(s) of a variableslice_max()– select rows with the highest value(s) of a variable
cereal |>
slice_max(order_by = sugars, n = 3) name manuf type calories protein fat sodium fiber carbo
1 Golden Crisp P cold 100 2 0 45 0 11
2 Smacks K cold 110 2 1 70 1 9
3 Apple Jacks K cold 110 2 0 125 1 11
4 Post Nat. Raisin Bran P cold 120 3 1 200 6 11
5 Total Raisin Bran G cold 140 3 1 190 4 15
sugars potass vitamins shelf weight cups rating
1 15 40 25 1 1.00 0.88 35.25244
2 15 40 25 2 1.00 0.75 31.23005
3 14 30 25 2 1.00 1.00 33.17409
4 14 260 25 3 1.33 0.67 37.84059
5 14 230 100 3 1.50 1.00 28.59278Efficiency note: It is more efficient (and less prone to user-error!) to use slice_max() or slice_min() than arrange() followed by filter() or slice_head().
Check In
Will the first cereal in the output of
arrange(.data = cereal, potass)be the cereal with the largest or the smallest amount of potassium?What can you add inside of
arrange()to change the default order?What does adding multiple variables to arrange do (e.g.
arrange(.data = cereal, potass, sugars)?
7.3.4 select()
We select which variables we would like to remain in the data.
var3:var5:select(df, var3:var5)will give you a data frame with columns var3, anything between var3 and var 5, and var5!(<set of variables>)will give you any columns that aren’t in the set of variables in parentheses(<set of vars 1>) & (<set of vars 2>)will give you any variables that are in both set 1 and set 2.(<set of vars 1>) | (<set of vars 2>)will give you any variables that are in either set 1 or set 2.c()combines sets of variables.
dplyr also defines a lot of variable selection “helpers” that can be used inside select() statements. These statements work with bare column names (so you don’t have to put quotes around the column names when you use them).
everything()matches all variableslast_col()matches the last variable.last_col(offset = n)selects the n-th to last variable.starts_with("xyz")will match any columns with names that start with xyz. Similarly,ends_with()does exactly what you’d expect as well.contains("xyz")will match any columns with names containing the literal string “xyz”. Note,containsdoes not work with regular expressions (you don’t need to know what that means right now).matches(regex)takes a regular expression as an argument and returns all columns matching that expression. We will learn about regular expressions later in the course!num_range(prefix, range)selects any columns that start with prefix and have numbers matching the provided numerical range.
There are also selectors that deal with character vectors. These can be useful if you have a list of important variables and want to just keep those variables.
all_of(char)matches all variable names in the character vectorchar. If one of the variables doesn’t exist, this will return an error.any_of(char)matches the contents of the character vectorchar, but does not throw an error if the variable doesn’t exist in the data set.
There’s one final selector. While the rest of the selectors use the variable names this lets you choose columns based on the actual values of the variables.
where()applies a function to each variable and selects those for which the function returns TRUE. This provides a lot of flexibility and opportunity to be creative.
Check In
Which variables will be in the output of
cereal |> select(fiber:vitamins)?What symbol(s) do you use to remove a variable from the dataset?
Which helper function lets you choose variables based on their values rather than their names?
7.3.5 mutate()
Check In
- What are the three arguments of the
if_else()function?
7.3.6 summarize()
Check In
- What are common summary functions you might want to use?
7.3.7 group_by()
Check In
- What happens when you group by two variables?
Check In
In groups match the dplyr verbs to your suggested steps:
What is the ratio of fiber to sugars in each cereal?
Create a new dataset that only has Nabisco cereals and displays the protein, fat, and sodium in each.
Create a table that shows, for each manufacturer the average and standard deviation of the grams of sugar in their cereals, along with how many cereals are in the data for each manufacturer. Order the table from most sugar (on average) to least.
Required Reading
To review what we covered this week, refer to Chapter 3: Data Transformation in R4DS https://r4ds.hadley.nz/data-transform.html
https://www.tidyverse.org/↩︎